- 저널 링크: nvshare | 2024 IEEE/ACM 46th
- 해당 연구를 GitHub grgalex/nvshare README에 나온 정보를 바탕으로 리뷰했습니다.
아래 인용 아티클의 영상 버전 및
nvshare데모: https://youtu.be/9n-5sc5AICY
I've written a Medium article on the challenges of GPU sharing on Kubernetes, it's worth a read.1
CUDA는 다들 아실 것 같아 생략합니다.
Compute Unified Device Architecture(CUDA)는 NVIDIA GPU에서 범용 컴퓨팅을 가능하게 하는 잘 확립된 플랫폼 및 API입니다. CUDA는 Python 및 C++와 같은 다양한 프로그래밍 언어와 함께 작동하도록 설계되었습니다. API를 통해 CUDA는 GPU의 가상 명령어 및 계산 요소에 대한 액세스를 제공합니다. CUDA 프로그램은 CPU에서 실행되는 호스트 코드와 GPU에서 실행되는 장치 코드의 혼합으로 구성됩니다.
CUDA Context는 CPU 프로세스에 해당하는 GPU입니다. GPU를 활용하기 위해 애플리케이션은 Context를 생성하고 해당 명령(예: 메모리 할당 및 계산)을 발행합니다. 각 Context는 자체 페이지 테이블 세트(가상 주소 공간)를 가지고 있으며 다른 Context의 메모리에 액세스할 수 없습니다. 동일한 GPU에 여러 Context가 동시에 존재하지만, 주어진 순간에는 하나만 작업을 실행할 수 있습니다.
블랙박스 CUDA 드라이버는 공개되지 않은 방식으로 동일한 GPU에서 실행되는 Context를 Time-Slice 합니다. 이 시간 조각은 몇 밀리초 단위입니다. GPU 메모리를 할당하는 표준 방법은 cuMemAlloc이라는 방법을 사용하는 것입니다.
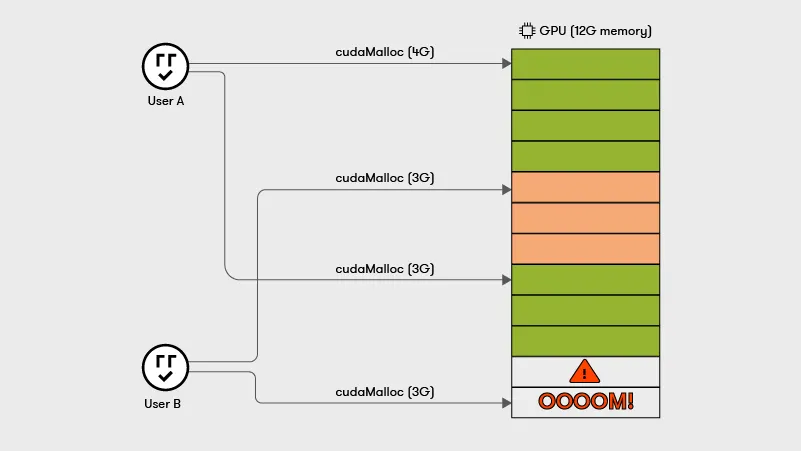
이러한 방식으로 할당된 모든 가상 메모리 바이트는 물리적 메모리 바이트에 의해 백업되어야 합니다. 이 개념의 함의는 모든 Context에 걸친 GPU 메모리 할당의 합계가 기껏해야 물리적 GPU 메모리 크기와 같을 수 있다는 것입니다. 예를 들어, 16GB GPU 메모리의 경우, 한 프로세스가 10GB를 할당하면 다른 프로세스는 치명적인 OOM 오류가 발생하지 않고 최대 6GB의 GPU 메모리를 할당할 수 있습니다.
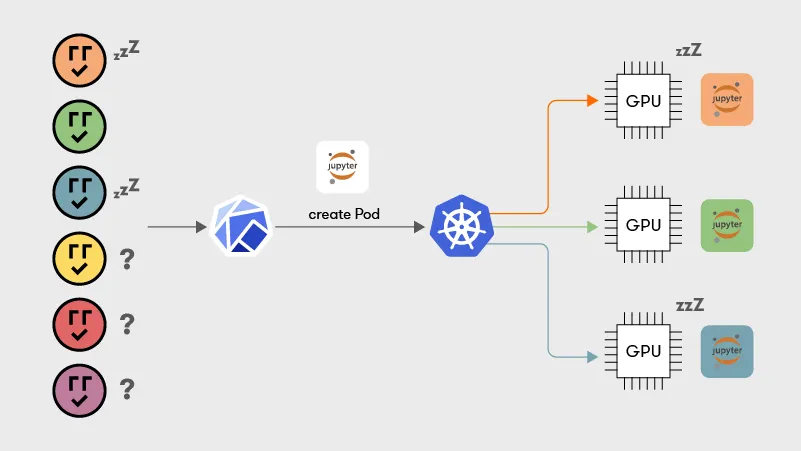
CUDA는 Context 별 메모리 할당 크기를 제한하는 방법을 제공하지 않습니다. 모든 응용 프로그램의 최고 GPU 메모리 사용을 선험적으로 알 수 없다는 점에 유의하십시오. 결과적으로, 쿠버네티스 및 Slurm2과 같은 Orchestrator 는 일대일 작업 대 GPU 할당 정책을 시행하고 공유를 허용하지 줌으로써 OOM 오류의 위협을 해결합니다.
통합 메모리(UM)3 하드웨어/소프트웨어 기술은 시스템의 RAM을 swap 공간으로 사용하여 GPU의 페이지 오류를 기능하게 하기 때문에 앞서 언급한 문제를 해결합니다. 페이지 가능한 메모리를 할당하기 위해, CUDA 프로그램은 cuMemAllocManaged 방법을 사용합니다. 페이지 오류가 발생하면 UM 하위 시스템(커널 모듈)은 누락된 페이지를 GPU 메모리로 가져오고 가장 오래전에 사용된(LRU) 교체 정책을 사용하여 모든 Context에서 호스트 RAM으로 퇴거할 페이지를 선택합니다. 따라서 UM은 모든 Context 에 걸친 메모리 할당의 합계가 GPU 물리적 VRAM 크기를 초과를 가능하게 만듭니다.
- Co-located processes limited by systeam RAM
- Each process can use the entire GPU memory
자세한 사항은 지원되는 GPU 섹션을 참고 바랍니다.
Thrashing은 페이지 오류를 처리하는 데 소요된 시간이 유용한 계산을 수행하는 데 소요된 시간을 압도하는 상황입니다. 개발자가 GPU 메모리를 과도하게 구독할 때, 함께 위치한 앱의 작업 세트(즉, 그들이 적극적으로 사용하고 있는 데이터; 할당의 하위 집합)가 해당 GPU VRAM에 맞지 않을 때 Thrashing 을 피해야 합니다. 블랙박스 CUDA 스케줄러의 지속적인 밀리초 스케일 Context 전환은 이 위험을 악화시킵니다.
요약: 페이지 오류가 자주 발생하면 시스템은 프로세스를 실행하는 것보다 이를 처리하는 데 더 많은 지연 시간을 소비하는 것을 Thrashing 이라고 부릅니다. 또한 이로 인해 전반적인 성능도 저하됩니다.
Nvshare는 Pascal 아키텍처에 도입된 Unified Memory의 동적 페이지 오류 처리 메커니즘에 의존합니다. 모든 Pascal(2016) 또는 최신 Nvidia GPU를 지원합니다. Linux 시스템에서만 테스트되었습니다.
(운영체제 개념) 페이지 오류 처리 메커니즘 소개
다른 분 블로그에서 가져왔습니다. [OS] Virtual Memory System
새로운 페이지를 메모리에 적재해야 하는데 저장공간이 부족한 경우, 어떤 것을 쫒아낼 것인가? ➜ 다시 사용안될 가능성이 큰 메모리를 쫒아내야 한다.
| 알고리즘 | 설명 |
|---|---|
| FIFO | 가장 오래전에 적재된 페이지를 버린다. |
| Second chance | FIFO를 약간 보완한 방식이다. 페이지의 reference bit를 사용하여 최근에 사용된 페이지에 "두 번째 기회"를 제공한다. |
| Clock | Second Chance를 원형으로 적용한 알고리즘이다. |
| Optimal Page Replacement(OPT) | 이론적인 모델 미래에 가장 오랫동안 사용되지 않을 페이지를 버린다. |
| LRU(Least Recently Used) | 가장 오래전에 참조된 페이지를 버린다. 제일 많이 사용하는 알고리즘이다. |
| NRU(Not Recently Used) | 가장 낮은 우선순위의 클래스에서 페이지를 선택하여 버린다. |
| NFU(Not Frequently Used) | Aging 알고리즘과 같이 사용하여 LRU를 근사적으로 구현 각 페이지에 대한 참조 횟수를 계산하여 메모리에서 가장 적게 사용된 페이지를 버린다. |
- 성능: OPT > LRU > CLOCK > FIFO
- A 명령어를 실행하고자 필요한 페이지가
- 마이너: 메모리에 있지만 현재 프로세스의 페이지 테이블에 없는 경우
- 메이저: 페이지가 메모리에 없고 디스크에서 가져와야 하는 경우
- 잘못된 페이징: 프로세스가 잘못된 메모리 주소에 접근하려고 할 때
- (CPU) Page Fault Handling 절차
- Page fault 발생
- CPU는 인터럽트(Page fault interrupt)를 걸어서 운영체제로 점프 - Fault를 일으킨 주소는 스택에 저장
- CPU 내부의 레지스터들도 스택에 저장
- OS가 SWAP에 존재하는 페이지를 메모리에 적재 후, 페이지 테이블 수정(valid bit = 1)
- 리턴 후 CPU는 A부터 실행
⠀위와 같은 과정을 Page Fault Handling라 한다.
- 일반 Interrupt가 걸리면 명령어 A를 다 끝낸 다음에 OS로 점프한다.
- 하지만, Page fault Interrupt는 인터럽트가 걸린 시점의 명령어(A)부터 다시 실행한다.
Page Fault Handling in Operating System - Geeks for Geeks Page Fault가 자주 발생하는 경우 시스템에 아래와 같은 영향을 미칩니다.
- Thrashing: 페이지 오류가 자주 발생하면 시스템은 프로세스를 실행하는 것보다 이를 처리하는 데 더 많은 시간을 소비하며, 그로 인해 전반적인 성능도 저하됩니다.
- 증가된 지연 시간: 디스크에서 페이지를 가져오는 것은 메모리에서 액세스하는 것보다 시간이 더 많이 걸리며, 이로 인해 더 많은 지연이 발생합니다.
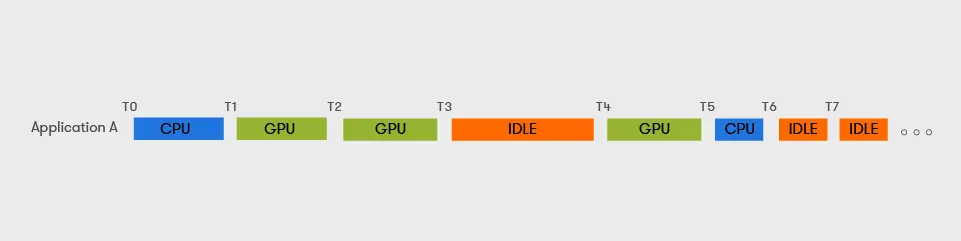
- 동일한 GPU에서 빈번하지 않게 GPU 버스트가 발생하는 2+ 프로세스/컨테이너 실행(예: 대화형 앱, ML 추론)
- GPU 버스트란 특정 GPU 작업을 연속적으로 처리하는 것,
- 주로 GPU 실행이 많이 필요한 작업을 수행할 때 일어난다.
- 동일한 GPU에서 2+ 비-대화형 워크로드(예: ML 교육)를 실행하여 총 완료 시간을 최소화하고 대기열을 줄입니다.
- 여러 프로세스/컨테이너 간의 단일 GPU 공유
- 아래 언급하는 코로케이션 프로세스를 (공동-위치 작업) 의미함
- 이 프로젝트에서 사용하는 코로케이션 프로세스는 NVIDIA MPS 와 같은 다른 접근 방식과 달리 서로 다른 CUDA contexts 를 사용하기 때문에 메모리 및 장애 격리가 보장됩니다.
- 투명성 (zero-config?): 준비한 앱 내부에서 코드 변경 이 필요하지 않습니다.
- 각 프로세스/컨테이너는 전체 GPU 메모리를 사용할 수 있습니다.
- Unified Memory 를 사용하여 GPU 메모리를 시스템 RAM으로 swap 합니다.
- 스케줄러는 Thrashing을 피하기 위해 겹치는 GPU 작업을 선택적으로 직렬화합니다(한 번에 TQ초 동안 하나의 앱에 대한 독점 액세스를 할당합니다)
- TQ가 경과하기 전에 작업이 완료되면 앱은 GPU를 해제합니다.
- Unified Memory: GPU VRAM을 동적 페이지 오류 처리(Dynamic Page fault handling)를 통해 마치 시스템 RAM 공간처럼 다루어 각 앱마다 메모리 공간 할당을 동적으로 기능하게 함
- 물리적 GPU 메모리 초과 활용: 동적 할당을 하게 되니 모든 앱의 실행된 동안 할당 되었던 최대 GPU 메모리 리소스를 합치면 물리적 VRAM 크기 초과를 가능하게 됩니다.
Unifined Memory 섹션 발췌: 페이지 오류가 발생하면 UM 하위 시스템(커널 모듈)은 누락된 페이지를 GPU 메모리로 가져오고 가장 최근에 사용된(LRU) 교체 정책을 사용하여 모든 Context에서 호스트 RAM으로 퇴거할 피해자 페이지를 선택합니다. 따라서 모든 Context 에 걸친 메모리 할당의 합계가 GPU 물리적 VRAM 크기를 초과를 가능하게 만듭니다.
Footnotes
-
Slurm workload manager. https://slurm.schedmd.com/documentation.html. [Online; accessed 22-October-2023]. ↩
-
Unified Memory Programming. https://docs.nvidia.com/cuda/cuda-cprogramming-guide/index.html#um-unified-memory-programming-hd. [Online; accessed 21-October-2023]. ↩